Les applications créées avec le framework Angular sont construites à partir de composants (« components » en anglais), ces derniers sont donc le point de départ idoine pour bien commencer dans le monde des tests.
En guise d’exemple, imaginez un composant qui affiche un calendrier. Il permettra à un utilisateur de sélectionner une date, de modifier la date sélectionnée, de faire défiler les mois et les années, etc. Il nous incombe de rédiger un cas de test pour chacune de ces fonctionnalités.
Dans cet article, nous aborderons les principales classes et fonctions de test, telles que TestBed, ComponentFixture et fakeAsync, qui nous aideront à tester nos composants. Une bonne compréhension de ces classes et fonctions est nécessaire pour écrire ces tests, le sujet de ces articles n’étant pas l’apprentissage du framework.
Retrouvez le code de cet article sur ce dépôt stackblitz :
Ou suivez pas à pas les instructions 😇 !
Tester un composant simple
La meilleure façon de se familiariser avec l’écriture de tests de composants est d’écrire quelques tests pour un composant assez simple. C’est à dire un composant avec très peu de fonctionnalités, ce qui va le rendre très facile à tester.
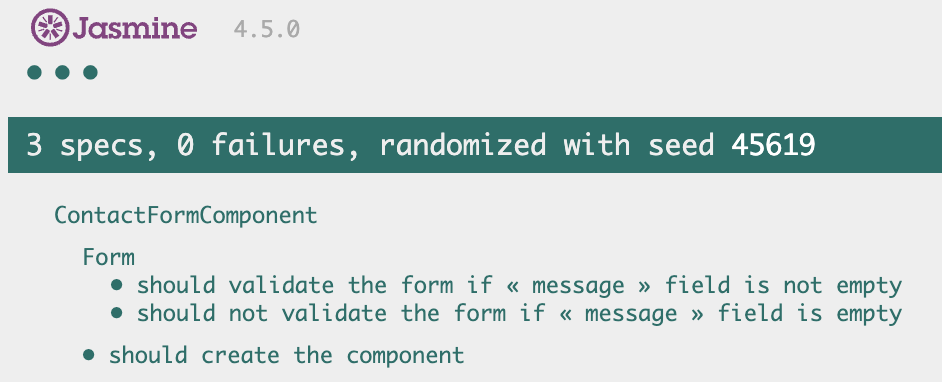
ContactFormComponent
Ce composant servira de support à nos premiers tests. Il s’agit d’un composant qui affiche un formulaire avec un seul champ (message) et un bouton pour envoyer le formulaire. Techniquement on ne va pas envoyer le message, car de toute façon tester l’envoi du message n’a pas sa place dans un test unitaire. Au lieu de ça, on affichera simplement un message de confirmation ou d’infirmation.
En pratique, cela donne un composant plutôt dépouillé :
Figure 3.1 – Plus simple tu meurs…
Notre composant support est prêt à être tester, alors c’est parti !
Réflexion : comment tester un composant
Avant de se jeter corps et âme dans l’écriture d’un test unitaire, nous devons d’abord nous poser les bonnes questions. Le sujet est important car beaucoup butent sur cette question simple : que dois-je tester dans un composant Angular ?
La réponse est au moins aussi simple que la question : il suffit simplement de s’assurer que le code du composant réagit comme prévu. On va donc se focaliser sur les méthodes du composant, en mettant de côté le template.
D’une manière un peu générale et abstraite, il faut essayer de se placer dans le contexte du composant, de son point de vu. Et de se demander : « comment doit réagir mon composant quand il se passe telle action ? ». Ou bien « si me composant exécute cette action, qu’est ce que cela engendre ? ».
Il faut également veiller à ne jamais dépasser le premier niveau d’enchaînement, c’est à dire qu’il faut s’intéresse seulement aux conséquences qui sont directement liées au composant. Par exemple, imaginons un composant qui envoie un formulaire d’inscription via un service (apiService) dédié. Ici on va simplement vérifier que la bonne méthode de notre service est appelée si le formulaire est valide, avec éventuellement les bons paramètres. On ne vérifie pas ce que la méthode du dit service fait, cela équivaudrait à un « test traversant ». Plus tard on testera en isolation notre service et c’est à cette occasion qu’on vérifiera son comportement.
Construction du test pas à pas
La première étape de la création du test consiste à importer les dépendances. De manière générale, ce type de test nécessitera deux dépendances, bien que dans notre cas précis seule la seconde dépendance sera utile :
① → la première est ContactFormComponent, à savoir le composant à tester.
② → la seconde est le « matériel Angular » si je puis m’exprimer ainsi, les outils qui vont nous aider à tester notre composant.
import { ComponentFixture, TestBed } from '@angular/core/testing'; ①
import { ContactFormComponent } from './contact-form.component'; ②
On notera que je fais toujours une séparation entre les dépendances provenant du framework et celles venant de la logique métier. Ici elle est matérialisée par un saut de ligne.
Maintenant, nous allons créer la suite de tests qui abritera tous les tests du composant. Après les instruction d’importation, ajoutons un bloc describe pour initier la suite de tests :
describe('ContactFormComponent', () => {
}
Ensuite, nous devons déclarer une variable nommée ContactFormComponent qui fait référence à une instance de ContactsFormComponent. Cette variable sera instanciée dans le bloc beforeEach des tests. Cela garantira une nouvelle instance du composant ContactsFormComponent à chaque nouveau test, ce qui empêchera les différents tests d’interférer les uns avec les autres. Sur la première ligne à l’intérieur de la fonction de rappel describe, ajoutons le code suivant :
let component: ContactFormComponent;
Ce qui pourrait se traduire par : « initialise moi la variable component qui sera de type ContactFormComponent ».
A ce stade il est important de noter que la variable n’est encore instanciée, seulement déclarée.
Par la suite, nous devrons donc instancier cette variable dans la fonction beforeEach de notre suite de tests :
import { ContactFormComponent } from './contact-form.component'; ①
describe('ContactFormComponent', () => {
let component: ContactFormComponent; ②
beforeEach(() => {
component = new ContactFormComponent(); ③
});
});
Bon on récapitule car je pense en avoir perdu au moins la moitié 😆 :
① → import des dépendances.
② → nous déclarons une variable component qui sera de type ContactFormComponent.
③ → la variable component est instanciée.
En procédant ainsi, on s’assure de toujours avec un composant « vierge » dans chaque test (qui ne sont pas encore écrits 😝). A présent, nous sommes prêt pour ajouter notre premier test : vérifier que le composant s’instancie correctement, ou dit autrement vérifier que le composant a un constructeur valide. On le fait avec le test suivant :
it('should create the component', () => {
expect(component).toBeTruthy();
});
Snippet 3.2 – Un test simple mais efficace.
Ici, on utilise le matcher toBeTruthy car on ne se soucie pas de la valeur testée, on veut juste s’assurer qu’elle soit vraie dans un contexte booléen. Mis bout à bout, notre fichier de test ressemble désormais au snippet 3.3 suivant :
import { ContactFormComponent } from './contact-form.component'; ①
describe('ContactFormComponent', () => { ②
let component: ContactFormComponent; ③
beforeEach(async () => {
component = new ContactFormComponent(); ④
});
it('should create the component', () => { ⑤
expect(component).toBeTruthy(); ⑥
});
});
Snippet 3.3 – Une première suite de tests complète.
Voyons tout ceci en détail :
① → import des dépendances.
② → déclaration de la suite de tests.
③ → déclaration d’une variable component qui sera de type ContactFormComponent. Sa portée se limitera au bloc describe.
④ → la variable component est instanciée avant chaque test car on se trouve dans la fonction beforeEach.
⑤ → déclaration du premier test unitaire.
⑥ → vérification que le constructeur du composant est valide.
Pour bien se rendre compte de ce que nous avons accompli, démarrons la suite de tests avec la commande suivante :
# ./node_modules/.bin/ng test
Jasmine devrait automatiquement ouvrir le navigateur Chrome grâce à Karma :
Figure 3.2 – Premier test d’un composant.
Terminer la suite de tests
Maintenant que l’on a une bonne vue d’ensemble sur la façon de structurer une suite de tests, nous pouvons ajouter quelques tests supplémentaires pour couvrir la totalité des fonctionnalités du composant. Voici ce que je propose de tester :
vérifier la validité du formulaire
vérifier qu’en cas d’erreur un message d’erreur s’affiche
vérifier qu’en cas de succès un message de confirmation s’affiche
vérifier qu’aucuns messages ne s’affiche initialement
Pour le premier cas, le test est trivial : nous devons faire deux tests :
si le champ message est vide, le formulaire ne doit pas être valide
si le champ message n’est pas vide, le formulaire doit être valide
Et comme nous allons faire deux tests pour un seul cas (validité du formulaire), on va même ajouter une petite section describe :
describe('Form', () => { ①
it('should validate the form if « message » field is not empty', () => { ②
component.contactForm.setValue({ ③
message: 'hello'
});
expect(component.contactForm.valid).toBeTruthy(); ④
});
it('should not validate the form if « message » field is empty', () => { ⑤
component.contactForm.setValue({ ⑥
message: ''
});
expect(component.contactForm.valid).toBeFalsy(); ⑦
});
});
Je vous dois quelques explications 🙃 :
① → on déclare une nouvelle « sous suite » de tests car les tests que l’on va écrire sont liés entre eux.
② → on déclare le premier test, qui doit vérifier que le formulaire est valide si l’unique champ (« message ») est renseigné.
③ → on rentre manuellement une valeur dans l’unique champ « message » du formulaire.
④ → on teste la propriété valid du formulaire, qui sera égale à true si le formulaire est valide, false sinon.
⑤ → le second test fait l’inverse du premier : il doit vérifier que le formulaire n’est pas valide si le champ « message » est vide.
⑥ → ici on s’assure que le champ « message » sera bien vide pour le test.
⑦ → cette fois, la propriété valid du formulaire doit retourner false, ce qui indique que le formulaire n’est pas valide.
A première vue, le point ⑥ peut paraître étrange. A quoi bon entrer une valeur vide dans le champ de formulaire alors que celui-ci l’est déjà de par sa construction 🤔 ? La réponse est simple : imaginiez qu’un beau jour vous décidiez, pour une raison quelconque, de « pré-remplir » le formulaire. Dans ce cas le test sera cassé, alors que la fonctionnalité sera toujours correcte.
On peut voir le résultat avec Jasmine :
Figure 3.3 – Le formulaire est prêt.
De manière à rendre les choses légèrement plus concises, on peut faire quelques modifications pour réduire la longueur de nos tests, bien qu’ici ils ne soient pas très long (pour le moment). C’est toujours mieux de prendre les bonnes habitudes dès le début 😋. Je pense plus particulièrement à la variable component.contactForm qui rend le test légèrement « verbeux ». On va donc isoler cette variable dans un bloc beforeEach, en lui donnant le nom de contactForm, histoire de rendre tout ceci plus clair :
import { ContactFormComponent } from './contact-form.component';
import { FormGroup } from "@angular/forms";
describe('ContactFormComponent', () => {
let component: ContactFormComponent;
let contactForm: FormGroup; ①
beforeEach(async () => {
component = new ContactFormComponent();
contactForm = component.contactForm; ②
});
it('should create the component', () => {
expect(component).toBeTruthy();
});
describe('Form', () => {
it('should validate the form if « message » field is not empty', () => {
contactForm.setValue({ ③
message: 'hello'
});
expect(contactForm.valid).toBeTruthy();
});
it('should not validate the form if « message » field is empty', () => {
contactForm.setValue({
message: ''
});
expect(contactForm.valid).toBeFalsy();
});
});
});
Snippet 3.4 – Résultat après optimisation.
① → la variable contactForm est initialisée avec le type FormGroup.
② → la variable est associée à la valeur component.contactForm avant chaque test. Le fait que ce soit fait avant chaque test ne pose aucuns problèmes.
③ → la variable contactForm est disponible dans nos blocs de tests it.
Passons maintenant aux deux cas suivants, qui par ailleurs se ressemblent comme deux gouttes d’eau :
vérifier qu’en cas d’erreur de l’envoi un message d’erreur s’affiche.
vérifier qu’en cas de succès de l’envoi un message de confirmation s’affiche.
Comme précisé plus haut, on n’envoie pas réellement un email, on se contente pour le moment d’afficher un message de succès (ou d’erreur) si toutes les conditions sont réunis. A savoir:
le formulaire doit être valide (ou non pour l’erreur d’envoi)
l’utilisateur clique sur le bouton « Envoyer »
Nous arrivons donc à la question centrale : comment simuler l’action de cliquer sur le bouton ? On pourrait retrouver notre bouton avec un sélecteur css puis déclencher un événement :
it('should call a function when the button is clicked', () => {
const button = fixture.debugElement.query(By.css('button')); // get the DebugElement for the button
button.nativeElement.click(); // simulate a click on the button
});
Snippet 3.5 – Exemple de ce qu’il ne faut pas faire.
Le problème de cette méthode est qu’elle rend le test très instable. Pour une bonne raison : quel est le meilleur sélecteur css à utiliser ? Je veux dire, ici on a qu’un seul bouton, mais si demain j’en ai un deuxième, le test casse. Mais pas la fonctionnalité. De plus, utiliser cette méthode revient aussi à vérifier que le framework fait se pourquoi on l’utilise, c’est à dire que l’évènement ngSubmit du formulaire fonctionne correctement. Et ce n’est pas à nous de le faire, on veut juste savoir si après avoir cliquer il se passe ce que nous voulons.
Ici la meilleur façon d’arriver à nos fins est donc d’activer manuellement la fonction submitForm, car c’est effectivement, grâce au framework, ce qu’il se passe : si je clique sur le bouton, l’évènement ngSubmit exécute la fonction submitForm.
Ce test se résume donc à tester la fonction submitForm du composant, on n’a donc pas besoin du template html pour arriver à nos fins. Ceci est vrai dans 99% des tests unitaires. Sinon ce n’est plus un test unitaire mais un test fonctionnel.
Arrêtons ici les digressions, passons à la pratique. Dans ce genre de tests, j’aime bien les regrouper dans une section « Comportement du composant », de cette façon on sait qu’on s’intéresse à une fonctionnalité qui nécessite une action utilisateur :
describe('Component behavior', () => { ①
it('shoud display an error message if the email is not sent', () => { ②
contactForm.setValue({message: ''}); ③
component.submitForm(); ④
expect(component.error).toBeTrue(); ⑤
expect(component.success).toBeFalse(); ⑥
});
it('shoud display a success message if the email is not sent', () => {
contactForm.setValue({message: 'Hi there!'});
component.submitForm();
expect(component.error).toBeFalse();
expect(component.success).toBeTrue();
});
});
A mon avis quelques explications s’imposent :
① → déclaration d’une nouvelle suite de tests, désormais on n’a l’habitude. 😋
② → déclaration du premier test unitaire.
③ → on s’assure que le formulaire sera invalide ce qui doit déclencher l’erreur.
④ → le formulaire est soumis.
⑤ → je vérifie que la variable component.error est à true, ce qui affiche le message d’erreur.
⑥ → je vérifie que la variable component.success est à false, ce qui masque le message de confirmation.
Vous l’avez compris, j’ai pris le raccourci suivant : un message (d’erreur ou de confirmation) est affiché si et seulement si sa valeur correspondante (component.error pour l’erreur et component.success pour la confirmation) est à true.
Sans doutes avez-vous pensé que nous aurions pu faire la chose suivante :
let fixture = TestBed.createComponent(ContactFormComponent);
const button = fixture.debugElement.query(By.css('span')).nativeElement;
expect(getComputedStyle(button).display).toEqual('none');
Et vous avez raison, mais comme précisé plus haut, cette méthode est à proscrire car source d’ennuis à la puissance 10. Par exemple, dans ce cas précis, qui me dit qu’il faut tester la propriété display plutôt que visibility ? Ou bien alors les deux ? Tirons à pile ou face ! 🤭
Pour ceux qui sont encore là, vous avez sans doutes notez qu’il manque notre dernier test :
vérifier qu’aucuns messages ne s’affiche initialement
Après avoir fait les deux cas, précédents, celui-ci ressemble à une promenade de santé 😉. En guise d’exercice, je vous laisse le faire par vous même.
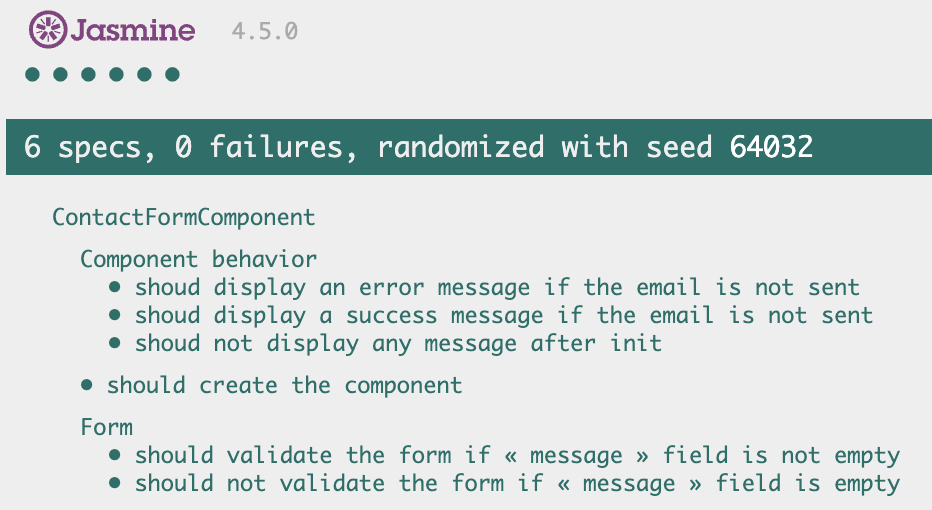
Récapitulatif
Que de chemin parcouru ! On en oublierait presque de tester tout en direct avec Karma/Jasmine. « Let’s dot it ! » comme disent les anglophones :
Figure 3.4 – Du vert partout !
Et voici le code final de notre suite de tests :
import { ContactFormComponent } from './contact-form.component';
import { FormGroup } from "@angular/forms";
describe('ContactFormComponent', () => {
let component: ContactFormComponent;
let contactForm: FormGroup;
beforeEach(async () => {
component = new ContactFormComponent();
contactForm = component.contactForm;
});
it('should create the component', () => {
expect(component).toBeTruthy();
});
describe('Form', () => {
it('should validate the form if « message » field is not empty', () => {
contactForm.setValue({
message: 'hello'
});
expect(contactForm.valid).toBeTruthy();
});
it('should not validate the form if « message » field is empty', () => {
contactForm.setValue({
message: ''
});
expect(contactForm.valid).toBeFalsy();
});
});
describe('Component behavior', () => {
it('shoud display an error message if the email is not sent', () => {
contactForm.setValue({message: ''});
component.submitForm();
expect(component.error).toBeTrue();
expect(component.success).toBeFalse();
});
it('shoud display a success message if the email is not sent', () => {
contactForm.setValue({message: 'Hi there!'});
component.submitForm();
expect(component.error).toBeFalse();
expect(component.success).toBeTrue();
});
it('shoud not display any message after init', () => {
expect(component.error).toBeFalse();
expect(component.success).toBeFalse();
});
});
});
Snippet 3.6 – La suite de tests complète.
Ce que nous avons appris
Nous venons d’apprendre qu’il est possible de tester de façon très direct des composants Angular simple, sans sortir l’artillerie lourde des outils de tests d’Angular. Et contrairement aux idées reçues, de tels composants sont monnaie courante, car nous devons toujours veiller à développer des composants qui soit clairs et concis, et donc facilement testables par la méthode que je présente ici.
Parfois, cependant, on n’aura d’autre choix que d’écrire des composants un peu plus complexes, notamment des composants avec des dépendances. C’est l’objet du prochain chapitre.
Avant d’aller plus loin dans le fonctionnement des tests pour Angular, on va d’abord se concentrer sur les tests de classes, qui ne nécessitent pas l’aide du framework de test fourni par Angular. Ce n’est en rien une perte de temps car dans la réalité il arrive souvent de tester « directement » des portions de code sans passer par les outils d’Angular 😉.
Comme nous l’avons vu dans la première partie, Jasmine est un « behavior-driven development (BDD) framework » qui est un choix très populaire pour celui qui veut efficacement tester son application JavaScript. L’avantage d’écrire des tests en suivant la méthodologie « BDD » est que le code de test produit sera proche du language courant, et donc facilement compréhensible par des équipes extérieures.
Mais avant cela, nous devons expliciter les principaux termes utilisés dans Jasmine.
Vocabulaire Jasmine
Il existe quelques fonctions importantes de Jasmine (describe, it et expect) avec lesquelles nous devons nous familiariser.
describe : utile pour regrouper une série de tests. Le groupe de tests ainsi créé est connu sous le nom de « suite de tests ». La fonction describe prend deux paramètres, une chaîne et une fonction de rappel, au format suivant :
describe(string describing the test suite, callback);
Il est possible d’utiliser autant de fonctions describe() que l’on veut. Cela dépend de la manière dont on voudra organiser nos tests en suites. Il est également possible d’imbriquer plusieurs fonctions describe() pour arriver à des suites de tests très structurés.
it : cette fonction crée un test spécifique, qui se place généralement à l’intérieur d’une fonction describe(). Comme cette dernière, la fonction it() prend deux paramètres (une chaîne et une fonction de rappel) au format suivant :
it(string describing the test, callback);
Le test sera créé à l’intérieur de la fonction de rappel en créant une assertion à l’aide de la fonction expect.
expect : cette fonction est la pierre angulaire du test unitaire. C’est elle qui va nous dire si le test « passe » ou bien « échoue ». On dit que l’on fait une assertion, c’est à dire qu’on va affirmer que quelque chose est vrai. Dans Jasmine, l’assertion est en deux parties : la fonction expect() elle même et le « matcher ». La fonction expect() recueille la valeur réelle provenant du code à tester (par exemple, une valeur booléenne). La fonction « matcher » quand à elle va. décrire la valeur attendue. Les exemples de fonctions « matcher » incluent toBe(), toContain(), toThrow(), toEqual(), toBeTruthy(), toBeNull(), et bien plus encore. Plus d’informations sur la page de Jasmine. On utilisera cette fonction de la façon suivante :
expect(value).matcher(expected_value)
Gardez à l’esprit que l’idéal est d’avoir une seule assertion par test. Lorsque vous avez plusieurs assertions dans un même test, chaque assertion doit être vraie pour que le test réussisse.
Premier test
Dans ce premier test, nous utiliserons la fonction describe() pour regrouper les tests dans une suite puis la fonction it() pour séparer les tests individuels. Ce test consiste à vérifier que la valeur booléenne true est égale à la valeur booléenne true.
describe('Chapter #2', () => { ①
it('first test', () => { ②
expect(true).toBeTrue(); ③
});
});
① → regroupe les tests dans une suite
② → sépare les tests individuels
③ → affirme que true est identique à true à l’aide du « matcher » toBeTrue()
Pour lancer la suite de tests, il suffit d’utiliser la commande suivante (nous sommes dans un contexte Angular 😉) :
# ./node_modules/.bin/ng serve
Jasmine utilise le navigateur Chrome, ce dernier devrait automatiquement s’ouvrir comme sur la figure 2.1.
Figure 2.1 – On vérifie que true est effectivement égal à true.
Et si le test échoue ?
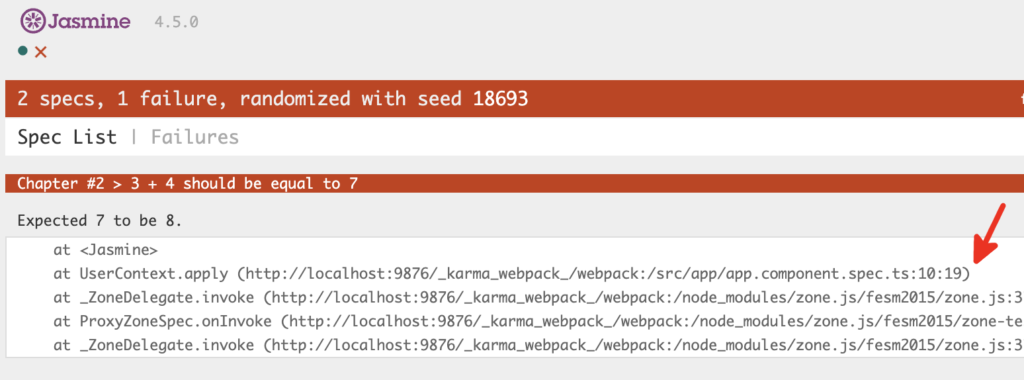
Dans ce cas Jasmine va tout de suite nous alerter. Ajoutons le test suivant à notre suite :
describe('Chapter #2', () => {
...
it('3 + 4 should be equal to 7', () => {
expect(3 + 4).toBe(8);
});
});
Snippet 2.1
Comme on peut s’en douter, lorsqu’un test échoue, on obtient une erreur. Sous le test défaillant, on aperçoit la trace de la pile d’exécution, ce qui est très utile pour repérer rapidement quelle portion du code pose problème. Ici on n’a que deux tests, mais dans un contexte d’une suite avec des milliers de tests, c’est très utile…
Figure 2.2 – Echec du test unitaire.
La pile d’exécution est toujours présentée dans le même ordre : les appels les plus récents en premier. Il suffit donc d’inspecter la première ligne de la pile pour évaluer d’un coup d’oeil la situation 😉 !
Tester une classe
Tester une classe Javascript se fait directement, sans passer par l’artillerie lourde du framework Angular. En guise d’exemple, nous allons créer deux fichiers :
Figure 2.3 – La classe User et son fichier de tests
src/app/models/user.ts : une classe (User) qui représente un utilisateur.
src/app/models/user.spec.ts : le fichier des tests unitaires. Il doit se trouver dans le même répertoire que le code qu’il teste (ici la classe User).
La classe User, qui représente un utilisateur, est très simple :
Avant d’aller plus loin, nous devons faire un peu de théorie. Dans les fichiers de tests, la première chose à faire est d’importer les dépendances. On pourra le faire comme ceci :
import { User } from "./user";
Ensuite, nous allez créer une suite de tests à l’aide de la méthode describe(), que l’on pourra nommer « User Class Test » :
describe('User Class Test', () => {
});
A l’intérieur de la fonction describe(), nous devons créer une variable qui contiendra notre futur objet instancié :
describe('User Class Test', () => {
let user: User;
});
Chaque variable doit être réinitialisée avant d’exécuter un test. La réinitialisation des variables qui ont été manipulées dans un test permet de s’assurer que chaque test s’exécute indépendamment et que les variables précédemment manipulées n’interfèrent pas avec les tests suivants. La prévention de telles interférences permet d’éviter des effets secondaires indésirables. Un exemple typique pourrait être la modification d’une variable dans un test, puis l’utilisation accidentelle de la variable modifiée dans un autre test.
La partie des tests où nous définissons des variables comme celle-ci est connue sous le nom de « set up ». Dans ce « set up », nous utiliserons la méthode beforeEach() pour initialiser la variable user à chaque exécution d’un test. Nous pouvons le faire directement sous la déclaration de la variable user :
beforeEach(() => {
user = new User(3, 'nicolas', 'test@test.com');
});
La fonctions beforeEach sera systématiquement utilisée pour configurer les tests et exécuter des expressions avant leur exécution. Ici on se contente d’initialiser un variables, mais parfois il y a plus de choses à faire.
Bien. Nous y sommes presque. Comment tester notre classe. Dans ce type de situation, il est usuel de s’assurer que l’objet s’instancie correctement. Pour ce faire, nous allons utiliser la négation d’un matcher existant, à savoir not.toBeNull(). C’est à dire que le succès du test sera atteint que si notre objet n’est « null » :
it('should have a valid constructor', () => {
expect(user).not.toBeNull();
});
Précisons qu’à l’instar de la fonction beforeEach, nous disposons d’une fonction similaire afterEach à ceci près qu’elle s’exécute après chaque test. Il s’agit de l’endroit idéal pour s’assurer que les instances de variables sont détruites, ce qui évitera les potentielles fuites de mémoire. Ici on pourrait réinitialiser notre variable :
afterEach(() => {
user = null;
});
Dans ce cas précis ce n’est pas très pertinent car le « set up » du test ré-initialise la variable à chaque fois.
A présent, assemblons tout ça pour obtenir un tout cohérent :
import { User } from "./user"; ①
describe('User Class Test', () => {
let user: User; ②
beforeEach(() => { ③
user = new User(3, 'nicolas', 'test@test.com');
});
it('should have a valid constructor', () => { ④
expect(user).not.toBeNull();
})
afterEach(() => { ⑤
});
});
src/app/models/user.spec.ts
Récapitulons les différentes étapes qui composent ce test :
① → on importe la classe User, l’unique dépendance de ce test.
② → déclaration de la variable user, de type User.
③ → la fonction beforeEach() sera exécutée avant chaque test unitaire, comme son nom l’indique 🙂.
④ → teste la variable user, qui ne doit pas être null.
⑤ → la fonction afterEach() sera exécutée après chaque test unitaire, comme son nom l’indique 🙂.
Devons-nous commencer la description du test (premier argument de it)avec « should » ? Vous l’avez peut-être remarqué mais jusqu’à présent tous les tests ont commencé leur description avec « should ». C’est une syntaxe courante qui rend les tests plus faciles à lire. Mais ce n’est pas une obligation – vous devez rédiger vos descriptions de la manière la plus logique pour vous et votre équipe.
Tout est prêt. Voyons le résultat dans Jasmine :
Figure 2.4 – Le test passe.
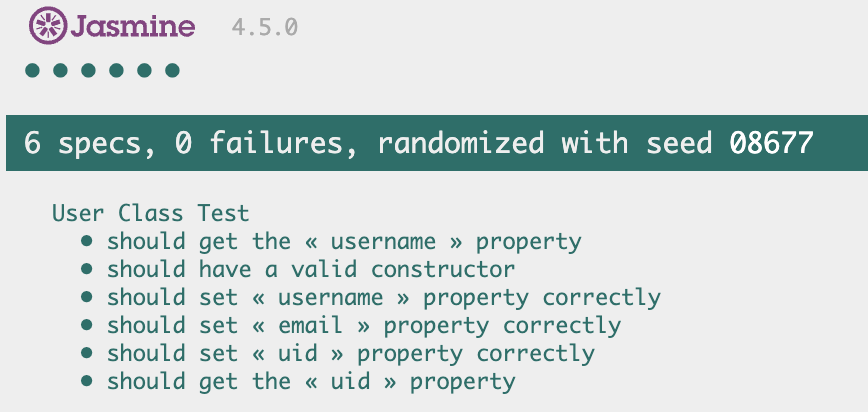
Folie ! Tout fonctionne à merveille. Améliorons tout de suite notre test en vérifiant que le constructeur initialise bien nos propriétés en ajoutant ces 3 tests unitaires :
Bien vérifieur que les nouveaux tests passent. Jasmine devrait donc afficher un résultat semblable à la figure 2.5 :
Figure 2.5 – Les setters fonctionnent.
Pour être complet, on pourra ajouter un test pour chaque méthode de la classe :
it('should get the « uid » property', () => {
expect(user.getUid()).toBe(3);
});
it('should get the « username » property', () => {
expect(user.getUsername()).toBe('nicolas');
});
Par la suite, s’assurer que tous les tests passent :
Figure 2.6 – Une belle suite de tests unitaires.
Ce que nous avons appris
L’écriture de tests unitaires de base peut s’avérer très utile sur certains éléments du framework Angular comme des fonctions simples, des classes et parfois même des services. En dehors de Jasmine, ces tests n’utiliseront pas de dépendances, ce qui les rends très facile à écrire et à maintenir.
On a commencé à explorer doucement la partie « comportement » du framework Jasmine en se forçant à décrire du mieux possible ce que le test unitaire doit vérifier. Une bonne pratique consiste à toujours écrire les énoncés des tests en anglais, car le code lui même utilise des mots anglais.
La plupart des tests unitaires que vous serez amené à écrire auront toujours le même schéma : d’abord une section d’importation des dépendances, puis une section pour créer la suite de tests, une section pour configurer les tests, une section pour les tests eux-mêmes et pour finir une section pour « nettoyer » la mémoire entre chaque tests.
La gestion des erreurs est une partie essentielle de RxJs, massivement utilisée dans le framework Angular.
La gestion des erreurs dans RxJS n’est pas aussi bien comprise que d’autres parties de la bibliothèque du même nom, en partie à cause d’une méconnaissance générale du « contrat Observable ».
Dans cet article, nous allons donc fournir un guide complet contenant les stratégies de gestion des erreurs les plus courantes utilisés dans les milieux professionnels, en commençant par expliquer les bases : le « contrat Observable ».
Le contrat Observable et la gestion des erreurs
Afin de bien comprendre la gestion des erreurs dans RxJs, il est indispensable de bien comprendre quelques notions indispensables. Premièrement, un flux de données (stream) ne peut s’arrêter qu’une seule fois. Un flux peut également se terminer normalement, ce qui signifie que :
le flux a terminé son cycle de vie sans aucunes erreurs.
une fois terminé, le flux n’émettra plus rien.
Comme alternative à l’achèvement, un flux peut également générer une erreur, ce qui signifie que :
le flux a terminé son cycle de vie avec une erreur.
une fois l’erreur levée, le flux n’émettra aucune autre valeur.
Notons que l’achèvement ou l’erreur s’excluent mutuellement :
si le flux se termine, il ne peut pas générer d’erreur par la suite.
si les flux produisent des erreurs, ils ne peuvent pas se terminer par la suite.
Notez également qu’il n’y a aucune obligation pour le flux de se terminer ou de sortir une erreur, ces deux possibilités sont facultatives. Mais un seul de ces deux peut se produire, pas les deux.
Cela signifie que lorsqu’un flux particulier se trompe, nous ne pouvons plus l’utiliser, selon le « contrat Observable ». Il faut toujours avoir à l’esprit ce principe, car c’est souvent ici qu’on retrouve des faiblesses dans le code.
A ce stade, il est donc très important de se poser la question : comment gérer des erreurs non prévues ?
Souscription RxJs et rappels d’erreurs
Pour connaître le comportement des erreurs RxJs, rien de mieux qu’un exemple. Créons un flux et souscrivons-y tout de suite. Rappelons à toutes fins utiles que subscribe() prend trois arguments optionnels :
une fonction rappel de succès, qui est appelée chaque fois que le flux émet une valeur.
une fonction rappel d’erreurs, qui est appelée uniquement si une erreur se produit. La fonction reçoit en paramètre l’erreur elle-même.
une fonction rappel d’achèvement, qui est appelée uniquement si le flux se termine.
Si le flux ne génère pas d’erreur, voici ce qu’affiche la console :
[Log] HTTP response ok. (vendor.js, line 5673)
[Log] HTTP request completed. (vendor.js, line 5699)
Comme nous pouvons le voir, ce flux HTTP n’émet qu’une seule valeur, puis il se termine, ce qui signifie qu’aucune erreur ne s’est produite.
Mais que se passe-t-il si le flux génère une erreur à la place ? Dans ce cas, nous verrons plutôt ce qui suit dans la console :
[Error] XMLHttpRequest cannot load http://localhost:8080/api/ due to access control checks.
[Log] HTTP Error. – HttpErrorResponse {headers: HttpHeaders, status: 0, statusText: "Unknown Error", …} (vendor.js, line 5685)
Comme nous pouvons le voir, le flux n’a émis aucune valeur et il a immédiatement généré une erreur. Après l’erreur, rien ne s’est produit.
Limitations du gestionnaire d’erreurs d’abonnement
La gestion des erreurs à l’aide de la fonction de rappel de subscribe() peut parfois suffire, mais cette approche est limitée. En l’utilisant, nous ne pouvons pas, par exemple, continuer le script ou émettre une valeur de secours alternative qui remplacerait la valeur attendue.
Voyons maintenant comment récupérer de ces erreurs aléatoires, à l’aide des opérateurs RxJs.
L’opérateur catchError
En programmation synchrone, nous avons la possibilité d’envelopper un bloc de code dans une clause « try » et d’intercepter toute erreur qui pourrait générée à l’aide d’un bloc catch, puis de gérer la dite erreur.
Voici à quoi ressemble la syntaxe de capture synchrone :
Ce mécanisme est très puissant car nous pouvons gérer en un seul endroit toute erreur qui se produit à l’intérieur du bloc try/catch.
Le problème est qu’en Javascript, de nombreuses opérations sont asynchrones, et un appel HTTP est un parfait exemple où les choses se produisent de manière asynchrone.
C’est là qu’entre en scène l’opérateur catchError.
Comment fonctionne catchError ?
Comme d’habitude et comme avec tout opérateur RxJs, catchError est simplement une fonction qui prend en entrée un « Observable » et renvoie aussi un « Observable ».
A chaque appel à catchError, nous devons lui passer une fonction que nous appellerons la fonction de gestion des erreurs.
L’opérateur catchError prend en entrée un « Observable » susceptible de provoquer une erreur. Avant que cela n’arrive, les valeurs passées en entrées sont directement reproduites en sortie.
Si aucune erreur ne se produit, l ‘ « Observable » produit par catchError sera le même que celui passé en entrée.
Que se passe-t-il lorsqu’une erreur est générée ?
Cependant, si une erreur se produit, la logique catchError va se déclencher. L’opérateur va prendre l’erreur et la transmettre à la fonction de gestion des erreurs.
Cette fonction est censée émettre un « Observable de remplacement » pour le flux qui vient de générer une erreur.
Rappelons-nous que le flux d’entrée de catchError a généré une erreur, donc selon le « contrat Observable » , nous ne pouvons plus l’utiliser.
C’est pour cette raison qu’un nouvel « Observable » a été émis, et c’est lui qui devra être utilisé dans le flux.
La stratégie « Catch and Replace » (capture et de remplacement)
Qu’avons nous fait ? Une petite explication s’impose :
d’abord nous passons à l’opérateur catchError une fonction, qui est la fonction de gestion des erreurs de tout à l’heure (①)
cette fonction n’est pas appelée immédiatement, et en général, elle ne l’est que très rarement
uniquement lorsque le flux http$ provoque une erreur
le cas échéant, un « Observable » sera émis par la fonction of(), ayant pour unique valeur un tableau vide ([])
la fonction of() construit un « Observable » qui n’émet qu’une seule valeur ([]) puis se termine
l’opérateur catchError va ensuite souscrire à ce nouvel « Observable », la valeur émise va donc remplacer la ou les valeurs du flux initial (http$)
-> Au final, le flux http$ n’émettra plus d’erreur !
Voici le résultat que nous obtenons dans la console :
[Log] HTTP response ok.
[Log] HTTP request completed. (vendor.js, line 5699)
Comme nous pouvons le voir, la fonction rappel de gestion des erreurs définie dans subscribe() n’est plus invoquée. Au lieu de cela, voici ce qui se passe :
la valeur de tableau vide [] est émise
le flux http$ est alors complété
Comme nous pouvons le voir, l’ « Observable » de remplacement a bien été utilisé pour fournir une valeur de secours par défaut ([]) aux abonnés du flux http$, malgré le fait que l’ « Observable » d’origine ait généré une erreur.
Notez que nous aurions également pu ajouter une gestion des erreurs locales, avant de renvoyer le remplacement Observable !
Voyons maintenant comment nous pouvons également utiliser catchError pour renvoyer l’erreur, au lieu de fournir des valeurs de secours.
throwError et la stratégie « Catch and Rethrow »
Commençons par remarquer que l’ « Observable » de remplacement fourni par catchError peut lui-même générer une erreur, comme tout autre « Observable ».
Et si cela se produit, l’erreur sera propagée aux abonnés de la sortie « Observable » de catchError.
Ce comportement de propagation des erreurs nous donne un mécanisme pour renvoyer l’erreur interceptée par catchError, après avoir traité l’erreur localement. Nous pouvons le faire de la manière suivante :
const http$ = this.http.get<Post[]>('/api/posts');
http$
.pipe(
catchError(err => { ①
console.log('Handling error locally and rethrowing it...', err); ②
return throwError(() => new Error(err)); ③
})
)
.subscribe({
next: res => console.log('HTTP response ok.', res),
error: err => console.log('HTTP Error.', err),
complete: () => console.log('HTTP request completed.')
}
);
Voyons étape par étape le fonctionnement de cette stratégie :
comme précédemment, nous attrapons l’erreur et renvoyons un « Observable » de remplacement (①)
mais cette fois-ci, au lieu d’émettre une nouvelle valeur de remplacement, nous gérons l’erreur localement dans la fonction catchError
on affiche simplement l’erreur dans la console, mais on pourrions à la place ajouter n’importe quelle logique de gestion des erreurs, comme par exemple afficher un message d’erreur à l’utilisateur (②)
nous renvoyons ensuite un « Observable » de remplacement qui est déjà en erreur, si je puis m’exprimer ainsi, à l’aide de la fonction throwError (③)
on peut créer une nouvelle erreur ou bien, comme ici, reprendre la même erreur (fournie par le paramètre de catchError)
cela signifie que nous avons réussi à « relancer » le flux en renvoyant avec succès l’erreur initialement renvoyée par l’entrée « Observable » de catchError vers sa sortie « Observable »
l’erreur peut maintenant être gérée par le reste de la chaîne « Observable », si nécessaire (plus précisément par la fonction rappel de subscribe())
L’intérêt majeur de cette stratégie est qu’elle nous donne la possibilité de gérer des « side effects » lors des erreurs (logging, alertes etc).
Comme nous pouvons le voir, la même erreur a été enregistrée à la fois dans le bloc catchError et dans la fonction de gestion des erreurs de la fonction subscribe(), comme prévu.
Utilisation de catchError plusieurs fois dans un flux
Notez que nous pouvons, si nécessaire, utiliser catchError plusieurs fois à différents points de la chaîne « Observable », et adopter différentes stratégies d’erreur à différents endroits de la chaîne.
Nous pouvons, par exemple, attraper une erreur dans la chaîne « Observable », la gérer localement et la relancer, puis plus bas dans la chaîne « Observable », nous pouvons à nouveau attraper la même erreur et cette fois fournir une valeur de repli (au lieu de relancer le flux) :
[Log] caught mapping error and rethrowing – HttpErrorResponse
[Log] caught rethrown error, providing fallback value (main.js, line 78)
[Log] HTTP response ok. – [] (0) (vendor.js, line 5673)
[Log] HTTP request completed. (vendor.js, line 5699)
Comme nous pouvons le voir, l’erreur a effectivement été renvoyée initialement, mais elle n’a jamais atteint la fonction de gestion des erreurs de la fonction subscribe(). Au lieu de ça, la valeur de secours [] a été émise, comme prévu.
L’opérateur « finalize »
En plus d’un bloc catch pour gérer les erreurs, la syntaxe Javascript synchrone fournit également un bloc finally pour exécuter du code quoi qu’il se passe dans le bloc try.
Le bloc finally est généralement utilisé pour libérer des ressources coûteuses, comme par exemple fermer des connexions réseau ou libérer de la mémoire.
Contrairement au code du bloc catch, le code du bloc finally sera donc exécuté même si une erreur est générée :
try {
// synchronous operation
const httpResponse = HttpClient('/api/posts');
}
catch(error) {
// handle error, only executed in case of error
}
finally {
// this will always get executed
}
RxJs nous fournit un opérateur qui a un comportement similaire au bloc finally, appelé l’opérateur finalize.
Exemple
A l’instar de l’opérateur catchError, il est possible d’ajouter plusieurs appels finalize dans la chaîne « Observable » (ou flux) :
[Log] caught mapping error and rethrowing – HttpErrorResponse
[Log] caught rethrown error, providing fallback value (main.js, line 79)
[Log] first finalize() block executed (vendor.js, line 5893)
[Log] HTTP response ok. – [] (0) (vendor.js, line 5673)
[Log] HTTP request completed. (vendor.js, line 5699)
[Log] second finalize() block executed (vendor.js, line 5893)
Il est intéressant de noter que le dernier bloc finalize est exécuté après les fonctions de rappels de subscribe().
La stratégie « nouvelle tentative » (retry)
Plutôt qu’émettre une nouvelle valeur lors d’une erreur, nous pouvons également simplement réessayer de re-souscrire au flux erroné.
Rappelons-nous, une fois que le flux est sorti en erreur, nous ne pouvons pas le récupérer, mais rien ne nous empêche de nous abonner à nouveau à l’« Observable » dont le flux a été dérivé et de créer un autre flux.
Voici l’idée générale :
nous allons souscrire une première fois à l’« Observable » http$ ce qui va créer un premier flux
si ce flux ne génère pas d’erreur, nous allons le laisser se terminer normalement
par contre, si le flux produit une erreur, nous allons alors souscrire à nouveau à l’« Observable » http$ ce qui va créer un nouveau flux
A quel moment re-souscrire ?
La grande question ici est de savoir quand allons-nous souscrire à nouveau à l’« Observable » http$ et ainsi réessayer d’exécuter le flux d’entrée ? Plusieurs possibilités :
immédiatement ?
après un petit délai en espérant que le problème soit résolu ?
allons-nous réessayer seulement un nombre limité de fois, puis générer une erreur ?
Afin de répondre à cette question, nous allons devoir introduire un nouvel opérateur : retry.
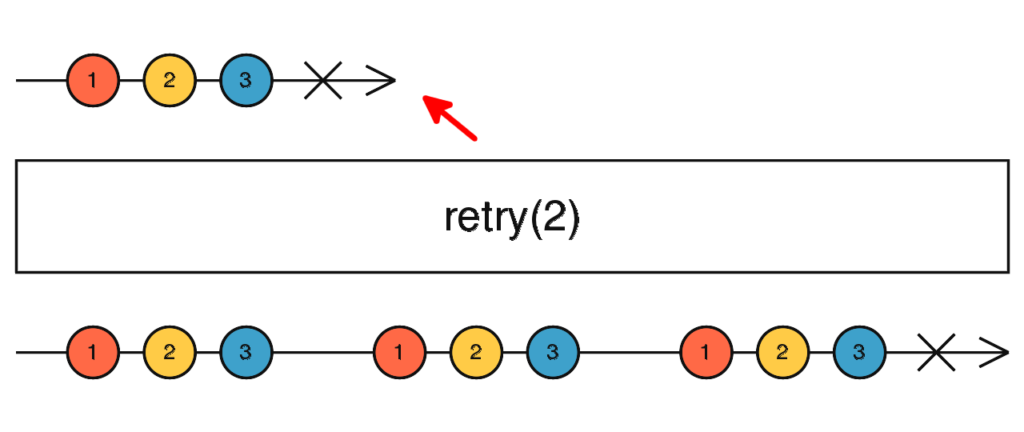
Diagramme marble de l’opérateur retry
Pour comprendre le fonctionnement de l’opérateur retry, examinons son diagramme :
La flèche rouge indique l’« Observable » http$.
Examinons ce qu’il se passe :
on souscrit à l’« Observable » http$, ses valeurs sont immédiatement émises (1, 2 puis 3) et directement renvoyée par retry
le flux se termine mais comme retry a pour paramètre 2, il re-souscrit tout de suite à l’« Observable » http$
les valeurs 1, 2 et 3 sont de nouveau ré-émises et
retry souscrit donc à nouveau à l’« Observable » http$, et ses valeurs sont à nouveau émisent vers la sortie « Observable » de retry
le même schéma se répète une seconde fois, plus le flux se termine mais cette fois retry ne re-souscrit pas une troisième fois !
Maintenant que nous comprenons comment fonctionne retry, voyons comment nous pouvons mettre en oeuvre notre stratégie.
Stratégie « nouvelle tentative immédiate »
Afin de refaire une tentative tout de suite après une erreur, tout ce que nous avons donc à faire est d’utilise l’opérateur retry.
Dans l’exemple suivant, nous allons faire une requête et si elle échoue, on va réessayer 3 fois :
l’opérateur retry souscrit à l’« Observable » http$ (①)
si aucunes erreurs n’est émise, l’opérateur retry est comme « transparent », c’est à dire qu’il reproduit en sortie les mêmes valeurs que celles qu’il reçoit
dans ce cas le flux se termine par la fonction idoine de rappel de subscribe() (⑤), puis est définitivement complété (⑥)
si une erreur survient, elle est « captée » par l’opérateur retry; ce dernier re-souscrit immédiatement l’« Observable » http$
si une erreur survient de nouveau, le même schéma se répète
l’opérateur retry fera 3 tentatives (car la propriété count est réglée à 3), puis émettra un « Observable d’erreur » qui sera intercepté car catchError (③)
catchError se contente ici de retourner un « Observable d’erreur » (il n’y a pas de side effect) puis l’« Observable » http$ se termine en erreur en invoquant la fonction idoine de rappel de subscribe() (④)
Stratégie « nouvelle tentative différée »
Améliorons les choses. Ajoutons un délai d’une seconde entre chaque tentative.
Cette stratégie est utile pour essayer de récupérer de certaines erreurs telles que, par exemple, des requêtes réseau échouées causées par un trafic élevé sur le serveur.
Dans les cas où l’erreur est intermittente, nous pouvons simplement réessayer la même demande après un court délai, et la demande peut passer une deuxième fois sans aucun problème
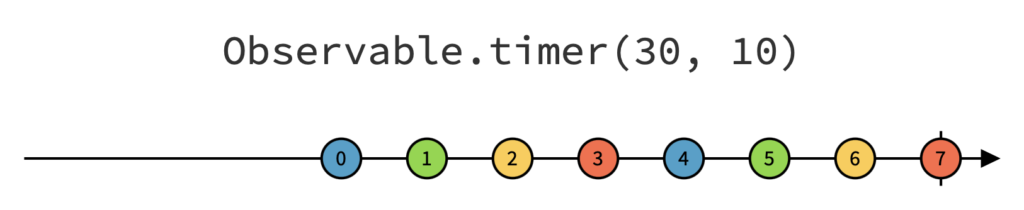
L’opérateur timer
Pour comprendre le fonctionnement de l’opérateur timer, examinons son diagramme :
La première valeur sera émise après 30ms, puis toutes les 10 ms.
Notez que le deuxième argument est facultatif, ce qui signifie que si nous le laissons de côté, notre « Observable » n’émettra qu’une seule valeur (0) après 30ms, puis se terminera.
L’opérateur timer semble le candidat idoine pour notre besoin.
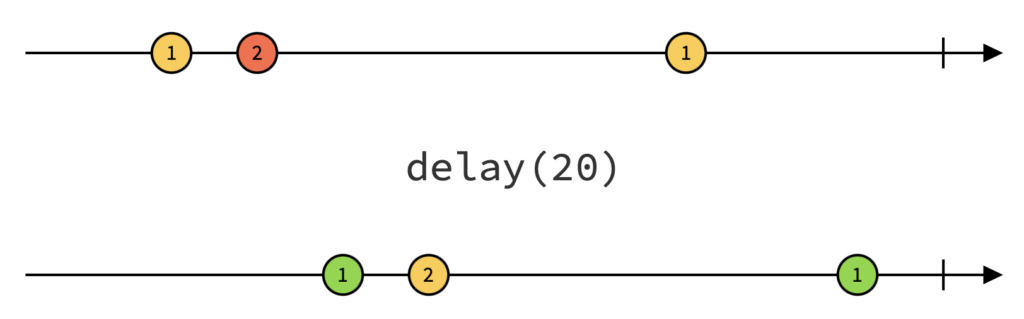
L’opérateur delay
Pour comprendre le fonctionnement de l’opérateur delay, examinons son diagramme :
Le fonctionnement de cet opérateur est trivial : toutes les valeurs émises en entrées sont restituées à l’identique après un temps donné (ici 20ms).
Essayons d’assembler tout ça pour atteindre notre objectif qui est de différé les tentatives :
[Log] Retrying… (main.js, line 77) [Log] Retrying… (main.js, line 77) [Log] Retrying… (main.js, line 77) [Log] HTTP Error. Stop after 4 attempts. – HttpErrorResponse {headers: HttpHeaders, status: 0, statusText: "Unknown Error", …}
Examinons en détail le cheminement :
le cheminement est très proche de la stratégie précédente
la différence est que nous introduisons un délai entre chaque tentative à l’aide du paramètre delay de l’opérateur retry (①)
la fonction de rappel que nous définissons renvoie un « Observable » qui devra émettre des valeurs à des intervals réguliers ou non
comme nous souhaitons des tentatives espacées régulièrement dans le temps, l’opérateur timer est le parfait candidat (②)
donc au lieu de faire immédiatement une nouvelle tentative, l’opérateur retry va attendre 1 seconde avant de re-souscrire à l’« Observable » http$ en cas d’erreur
la limite de 3 tentatives est encore présente comme précédemment
on affiche un petit message dans la console avant chaque tentative (③)
le reste du traitement est similaire à la stratégie précédente
Dans la console, le même affichage :
[Log] Retrying… (main.js, line 77)
[Log] Retrying… (main.js, line 77)
[Log] Retrying… (main.js, line 77)
[Log] HTTP Error. Stop after 4 attempts. – HttpErrorResponse {headers: HttpHeaders, status: 0, statusText: "Unknown Error", …}
On pourra visualiser l’évolution dans l’onglet réseau :
Les flèches rouges indiquent les tentatives de requête.
Comme nous pouvons le voir, les tentatives n’ont eu lieu qu’une seconde après l’apparition de l’erreur, comme prévu.
Conclusion
A travers cet article, j’ai essayé de vous présenter plusieurs stratégies pour bien gérer ses erreurs avec Angular / RxJs.
Comme nous l’avons vu, comprendre la gestion des erreurs RxJs consiste avant tout à comprendre les principes fondamentaux du « contrat Observable ».
Nous devons garder à l’esprit qu’un flux donné ne peut se mettre en erreur qu’une seule fois, et cela est exclusif avec l’achèvement du flux ; une seule des deux éventualités se produira.
Afin de récupérer d’une erreur, le seul moyen est de générer d’une manière ou d’une autre un flux de remplacement comme alternative au flux sortant erroné, comme cela se produit dans le cas des opérateurs catchError ou retry.
Si vous avez des questions ou des commentaires, faites-le moi savoir dans les commentaires ci-dessous et je vous répondrai.
Un code mal écrit, des fonctionnalités buggées et/ou de mauvaises pratiques de « refactoring » peuvent conduire à des applications peu fiables. Rédiger de bons tests aidera à détecter ces types de problèmes et à les empêcher d’affecter négativement votre application.
Il est essentiel de tester minutieusement votre application si vous souhaitez la faire évoluer durablement.
L’un des principaux objectifs lors de l’écriture de tests est de se prémunir contre les « régressions », c’est à dire des fonctionnalités qui cessent de fonctionner suite à une mise à jour du code, aussi minime soit-elle. Si vous avez déjà développé une application Angular, vous devez savoir que c’est un excellent framework pour créer des applications Web et Web mobiles testables. C’était d’ailleurs l’un des objectifs lors de son élaboration.
Le principal défaut d’Angular est le manque crucial de documentation à son sujet. Même la documentation officielle n’est pas simple à appréhender. Ce manque est encore plus criant lorsqu’on s’intéresse aux tests : un vrai parcours du combattant ! C’est pour cette raison qu’on trouve beaucoup d’applications sans le moindre test ! Les développeurs ont pensé qu’ils perdraient trop de temps à apprendre à tester le framework. Nous verrons combien cette erreur peut être fatale 🤔 !
Un autre défaut d’ Angular qui revient assez souvent : il est complexe à utiliser. Cependant il ne s’agit pas là d’un défaut, mais de son meilleur atout : il est difficile à appréhender car il s’agit d’un des meilleurs frameworks à disposition. Angular est aux framework Js ce que la formule 1 est à l’automobile : la performance avant tout.
Je ne vous apprendrai rien, il existe deux types de tests : les tests unitaires et les tests E2E. La majeure partie de mon propos tournera autour de ces deux types de tests.
Les tests unitaires testent des portions de code en « isolation ». J’expliquerai comment écrire des tests unitaires pour les composants, les directives, les « pipes », les services et le routage, à l’aide d’outils ultra connus que sont Karma et Jasmine. Petit rappel succinct de tous ces termes qui devraient vous être familier :
composants : morceaux de code utilisés pour « encapsuler » des fonctionnalités qui seront très facilement réutilisable dans toute l’application. Les composants sont un type de directives (voir puce suivante), sauf qu’ils incluent une vue ou un modèle HTML.
directives : utilisées pour manipuler des éléments qui existent dans le DOM. Elles peuvent ajouter ou supprimer des éléments du DOM. ngFor, ngIf et ngShow sont des directives fournies par Angular.
pipes : utilisé pour transformer les données. Par exemple, pour transformer un entier en devise.
services : bien que les services n’existent techniquement pas dans Angular, le concept est toujours important. On utilisera des services pour récupérer des données, puis les injecter dans les composants.
routage : permet aux utilisateurs de naviguer d’une vue à l’autre lorsqu’ils effectuent des tâches dans l’application Web.
Introduction aux 2 types de tests
Les tests unitaires et les tests E2E sont les deux types de tests que vous rencontrerez dans ce document. Examinons-les un peu plus en détail 🔎.
Tests unitaires
Les tests unitaires sont utilisés pour tester de portions de code d’une application, généralement des fonctions ou des méthodes. L’objectif de ces tests est de vérifier que chaque « fragment » de code fonctionne correctement (c’est à dire comme attendu)
Ils servent aussi à détecter des erreurs ou des bugs le plus tôt possible dans le processus de développement. Les avantages de l’utilisation massive des tests unitaires sont qu’ils sont rapides, fiables et reproductibles, à condition de les écrire correctement et de les exécuter dans le bon environnement.
Jasmine, qui est un « behavior-driven development framework », est recommandé par Google pour écrire des tests unitaires. Nous l’utiliserons donc tout au long de ce document. Ci-après, le plus basique des tests unitaires :
describe('Exemple de test', () => {
it('true is true', () => {
expect(true).toEqual(true); ①
});
});
Snippet 1.1 – Exemple de test unitaire.
① → Vérification d’intégrité qui vérifie que vrai est égal à vrai.
Le snippet 1.1 fait une seule chose : il vérifie que la valeur booléenne true est égale à la valeur booléenne true. Il s’agit d’un test de contrôle qui ne sert qu’à vérifier que l’environnement de test est fonctionnel.
Ci-après un exemple à peine plus élaboré : on vérifié que les getters/setters de la classe « User » fonctionne comme attendu :
describe('Test User getters and setters', () => {
it('The user name should be Nicolas', () => {
const user = new User();
user.name = 'Nicolas';
expect(user.name).toEqual('Nicolas'); ①
});
});
Snippet 1.2 – Un test plus élaboré.
① → Vérifie que le nom de l’utilisateur est le bon.
Bien que les tests unitaires sont plutôt fiables, ils ne reproduisent pas les interactions réelles avec les utilisateurs.
Tests E2E (End to End)
Les tests E2E ont pour but de tester les fonctionnalités d’une application en simulant le comportement de l’utilisateur final. Par exemple, on peut avoir un test E2E qui va vérifier si une fenêtre modale apparaît correctement après la soumission d’un formulaire ou si une page affiche certains éléments lors du chargement de la page, tels que des boutons ou du texte.
Les tests E2E sont vraiment performants du point de vue de l’utilisateur final. Mais ils s’exécutent lentement, et cette lenteur peut être la source de faux positifs qui échouent à cause des comportements asynchrones. Pour cette raison, il est toujours préférable d’écrire des tests unitaires au lieu de tests E2E, et ce dans la mesure du possible. Enfin, notons que l’équipe d’Angular recommande l’utilisation de Protractor E2E.
Etant donné la tâche à accomplir, un test E2E est plus consistant que son homologue unitaire. Le snippet 1.3 propose un test E2E tout simple.
import {browser} from 'protractor';
describe('My App test', () => { ①
it('should be the correct title', () => { ②
const appUrl = 'http://my-app/';
const expectedTitle = 'My first E2E test';
browser.get(appUrl);
browser.getTitle().then((actualTitle) => {
expect(actualTitle).toEqual(expectedTitle); ③
});
});
});
Snippet 1.3 – Un test E2E simple
① → Le bloc « describe » résume en une phrase la suite de tests à exécuter.
② → Le bloc « it » indique le commencement d’un test. Le premier paramètre contient un bref descriptif de ce qui est attendu, et le deuxième paramètre est une fonction callback qui va décrire le test.
③ → Le test lui même : le titre doit être équivalent à ce à quoi on s’attend.
Tests unitaires vs tests E2E
Les tests unitaires et les tests E2E présentent des avantages différents. Nous avons déjà un peu discuté de ces avantages, le tableau 1.1, condense tout ce qui a été dit auparavent.
Caractéristique
Test unitaire
Test E2E
Rapidité
Rapide
Lent
Fiabilité
Très bonne
Moyenne (code asynchrone)
Renforcement de la qualité du code
Permet d’identifier un code inutilement complexe
N’aide pas à écrire un code meilleur car l’application est testée « depuis l’extérieur ».
Coût
Faible car rapide à écrire
Plus élevé que les tests unitaires car leur écriture prend plus de temps, l’exécution est lente et les tests peuvent être irréguliers, et la fiabilité douteuse
Reproduction des interactions utilisateur
Possible mais les interactions complexes ne sont pas testables
Le point fort des tests E2E. Par design ils sont fait pour tester les interactions
Tableau 1.1 : comparaison tests unitaires et E2E.
Examinons chacune de ces fonctionnalités une par une :
vitesse : on l’a vu, les tests unitaires fonctionnent sur de petits morceaux de code, ils peuvent donc s’exécuter rapidement. Les tests E2E reposent sur des tests via un navigateur, ils ont donc tendance à être plus lents, parfois même très lent.
fiabilité : étant donné que les tests E2E ont tendance à impliquer davantage de dépendances et d’interactions complexes, ils peuvent être instables, ce qui peut entraîner des faux positifs. L’exécution de tests unitaires donne rarement des faux positifs. Si un test unitaire bien écrit échoue, vous pouvez être sûr qu’il y a un problème avec le code.
renforcement de la qualité du code : l’un des principaux avantages de l’écriture de tests est qu’elle contribue à renforcer la qualité du code. L’écriture de tests unitaires peut aider à identifier un code inutilement complexe qui peut être difficile à tester. En règle générale, si vous avez du mal à écrire des tests unitaires, votre code peut être trop complexe et nécessiter une refactorisation.
Je l’ai déjà dit, mais insistons bien sur ce point : écrire des tests E2E n’aidera jamais à écrire un code de meilleure qualité. Car les tests E2E testent d’un point de vue du navigateur, ils ne testent donc pas directement le code.
rentabilité : parce que les tests E2E prennent plus de temps à s’exécuter et peuvent échouer à des moments aléatoires, un coût doit être associé à ce temps. On ne peut pas dire que ce temps soit perdu, mais il a un certain coût. L’écriture de tels tests peut également prendre plus de temps, car ils s’appuyent sur des interactions complexes qui peuvent échouer, si bien que les coûts de développement augmentés en conséquence.
reproduction des interactions des utilisateurs : leur capacité à imiter les interactions des utilisateurs en font des tests très puissants, au plus près de la réalité. À l’aide de Protractor, il est possible d’écrire et exécuter des tests comme si un véritable utilisateur interagissait avec l’interface utilisateur.
En résumé, les deux types de tests sont importants pour tester minutieusement une application Angular. Les tests unitaires couvrent un large spectre de possibilités, mais on ne saura jamais de se passer des tests E2E qui prendront en charge les fonctionnaires clés de l’application.
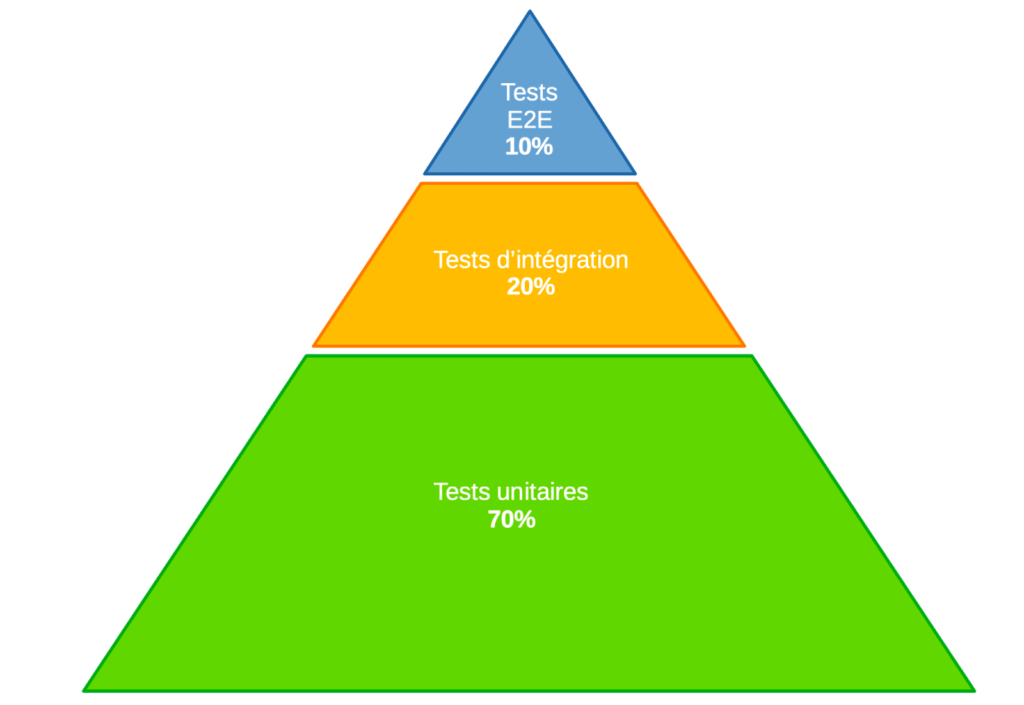
En règle générale, il y aura toujours plus de tests unitaires que de tests E2E, comme le montre la désormais célèbre pyramide de Mike Corn :
Figure 1.1 : répartition des types de tests.
Vous avez peut-être remarqué que la pyramide comprend des tests d’intégration. Les tests d’intégration et les tests E2E sont similaires en ce qu’ils vérifient que les différentes parties d’un système fonctionnent bien ensemble, mais ils ont des objectifs et des scopes différents. Pour nos besoins, nous allons déployer les tests d’intégration dans les tests E2E par soucis de simplicité.
Conclusion
Angular fournit un excellent cadre (c’est un framework 😎) pour créer des applications Web et mobiles facilement testables. Il s’appuie fortement sur le concept de composants pour développer des applications.
il existe 2 types de tests lors du développement d’applications : les tests unitaires et les tests E2E. Nous utiliserons des tests unitaires pour tester le code brut, tandis les tests E2E nous permettrons de simuler les interactions de l’utilisateur.
Protractor, Jasmine et Karma sont les principaux outils recommandés pour tester des applications Angular. Ces outils sont eux-même écrits en JavaScript et s’exécutent automatiquement pendant le développement.
La journalisation, c’est l’assurance vie du développeur : quand un client vous signale que son application fonctionne mal par intermittence, les marges de manoeuvres sont limitées. Heureusement, Symfony dispose d’outils plutôt sympathiques pour nous aider à diagnostiquer un incident passé. Bienvenue dans le monde de la journalisation ! 🙂
Notons que Symfony utilise le désormais célèbre monolog. Comme tous les services, il est facilement accessible sous forme de service (merci l’injection de dépendance) dans n’importe contrôleur :
namespace App\Controller\Api;
use Symfony\Bundle\FrameworkBundle\Controller\AbstractController;
use Psr\Log\LoggerInterface;
class FooController extends AbstractController
{
public function edit(LoggerInterface $logger)
{
$logger->info('Hey ! I am writing in logs !!');
}
}
Et voilà, nous savons déjà écrire dans les logs Symfony ! 😇 Ah ah, c’est bien beau tout ça, mais où retrouver ces messages (ou entrées logs) ? Eh bien malheureusement, à ce stade, il se peut qu’il ne se passe rien (ou presque) et par conséquent nos messages sont perdus dans l’immensité de l’univers Symfony. Si cela arrive, c’est que le bundle monolog n’est pas installé. Il va donc devoir le faire manuellement :
# composer require symfony/monolog-bundle
Une fois le problème résolu, on peut (enfin) voir apparaître nos messages dans le Symfony profiler :
Fig 1 – Première journalisation.
Handlers (gestionnaires)
A chaque fois qu’on va envoyer une entrée vers monolog (comme ci dessus), ce dernier va appeler la liste (dans l’ordre) des « handlers » (on appelle ça une pile) définis et leur passer la dite entrée. Un « handler » peut être perçu comme un gestionnaire qui va écrire le message quelque part (fichier, base de données, mail, etc) sous certaines conditions. Sous Symfony 6, en mode dev, on a les 2 gestionnaires suivants (config/packages/monolog.yaml) :
when@dev:
monolog:
handlers:
main: ①
type: stream ②
path: "%kernel.logs_dir%/%kernel.environment%.log" ③
level: debug ④
channels: ["!event"] ⑤
console: ①
type: console ②
process_psr_3_messages: false
channels: ["!event", "!doctrine", "!console"]
Fichier de configuration Monolog.
Un éclaircissement s’impose :
① → main et console sont les noms des gestionnaires.
② → type défini le type du gestionnaire. Pour l’instant on se cantonne à stream (système de fichier).
③ → en cas de type « stream », on indique le chemin fu fichier qui va stocker les entrées.
④ → level est le niveau d’erreur minimal requis pour déclencher le gestionnaire.
⑤ → channels permet d’indiquer quelles catégories d’entrées sont autorisées ou non.
J’admets, ça déroute un peu au début… La question est : que fait le gestionnaire lorsqu’il reçoit une entrée ? Réponse : cela dépend d’abord du niveau d’erreur et du « channel ».
Les gestionnaires sont appelés dans l’ordre dans lequel ils sont définis dans la clé handlers. Pour cette raison, il est conseillé de ne pas utiliser plusieurs fichiers de configuration et d’utiliser l’annotation Symfony when@dev.
Niveaux d’erreurs
Dans l’ordre (du moins important au plus important), les niveaux d’erreurs (« levels ») disponibles dans monolog :
debug
info
notice
warning
error
critical
alert
emergency
Le niveau d’erreurs va servir à Monolog pour déterminer si le gestionnaire doit être utilisé ou non. Car comme je l’ai dit plus haut, à chaque fois que l’on écrit :
$logger->...
Monolog va tester tous les gestionnaires définis dans le fichier de configuration et déterminer à chaque fois s’il doit traiter la demande. Reprenons l’exemple précédant :
$logger->info('Hey ! I am writing in logs !!');
D’après le fichier de configuration, nous avons deux gestionnaires : « main » et « console ». Dans l’ordre, :
Monolog regarde le niveau d’erreur (clé level) du gestionnaire « main » : ici c’est debug.
debug est le niveau minimal requis pour que le gestionnaire « main » traiter le message. Comme on a utilisé la méthode info ($logger->info), le message a un niveau d’erreur « info » qui est supérieur à « debug ». Le gestionnaire « main » traite le message.
Monolog regarde le niveau d’erreur du gestionnaire « console » : ici c’est debug car la clé level est absente de la définition de ce gestionnaire.
« debug étant le niveau d’erreur minimal, le gestionnaire « console » ne peut que traiter le message.
Prenons un autre exemple. D’abord modifions la configuration Monolog comme ci-après :
① → le niveau minimal d’alerte du gestionnaire « main » est maintenant warning.
Puis exécutons ce code :
use Psr\Log\LoggerInterface;
class FooController extends AbstractController
{
public function edit(LoggerInterface $logger)
{
$logger->debug('Hey ! I am writing in logs !!'); ①
$logger->info('Hey ! I am writing in logs !!'); ②
$logger->notice('Hey ! I am writing in logs !!'); ③
$logger->warning('Hey ! I am writing in logs !!'); ④
$logger->error('Hey ! I am writing in logs !!'); ⑤
$logger->critical('Hey ! I am writing in logs !!'); ⑥
$logger->alert('Hey ! I am writing in logs !!'); ⑦
$logger->emergency('Hey ! I am writing in logs !!'); ⑧
}
}
Que va t’il se passer ? Comme tout à l’heure voyons le déroulé des opérations, dans l’ordre. La première ligne à traiter est ① :
Monolog regarde le niveau d’erreur (clé level) du gestionnaire « main » : warning.
le niveau du message est debug, ce qui est inférieur à warning. Le gestionnaire ne traite pas le message.
Monolog regarde le niveau d’erreur du gestionnaire « console » : debug.
le niveau du message est debug, ce qui est égal à debug. Le gestionnaire « console » traite le message.
Comme il n’y a plus de gestionnaires dans la pile, on passe à la ligne ② :
Monolog regarde le niveau d’erreur du gestionnaire « main » : warning.
le niveau du message est info, ce qui est inférieur à warning. Le gestionnaire ne traite pas le message.
Monolog regarde le niveau d’erreur du gestionnaire « console » : debug.
le niveau du message est info, ce qui est supérieur à debug. Le gestionnaire traite le message.
Comme il n’y a plus de gestionnaires dans la pile, on passe à la ligne ③ :
Monolog regarde le niveau d’erreur du gestionnaire « main » : warning.
le niveau du message est notice, ce qui est inférieur à warning. Le gestionnaire ne traite pas le message.
Monolog regarde le niveau d’erreur du gestionnaire « console » : debug.
le niveau du message est notice, ce qui est supérieur à debug. Le gestionnaire traite le message.
Comme il n’y a plus de gestionnaires dans la pile, on passe à la ligne ④ :
Monolog regarde le niveau d’erreur du gestionnaire « main » : warning.
le niveau du message est warning, ce qui est égal à warning. Le gestionnaire traite le message.
Monolog regarde le niveau d’erreur du gestionnaire « console » : debug.
le niveau du message est warning, ce qui est supérieur à debug. Le gestionnaire traite le message.
Et ainsi de suite, inutile d’aller plus loin, à partir de la ligne ④ les deux gestionnaires sont utilisés, contre un seul avant la ligne ④. Donc si vous avez suivi 😝, et je suis sûr que c’est le cas, on retrouve 5 lignes dans le gestionnaire « main » :
[2023-03-20T19:45:56.784066+00:00] request.INFO: Matched route "_wdt". [...]
[2023-03-20T19:51:05.648407+00:00] app.WARNING: Hey ! I am writing in logs !! [] []
[2023-03-20T19:51:05.653301+00:00] app.ERROR: Hey ! I am writing in logs !! [] []
[2023-03-20T19:51:05.654188+00:00] app.CRITICAL: Hey ! I am writing in logs !! [] []
[2023-03-20T19:51:05.655030+00:00] app.ALERT: Hey ! I am writing in logs !! [] []
[2023-03-20T19:51:05.656267+00:00] app.EMERGENCY: Hey ! I am writing in logs !! [] []
Notez que la pile des gestionnaires est toujours appelée en totalité, c’est à dire qu’une même entrée peut être écrite à plusieurs endroits (l’utilisation d’un gestionnaire n’arrête pas le traitement de la pile).
Format d’une entrée log
Dans le paragraphe précédent, nous avons vu qu’une entrée dans un log ressemble à ceci :
[2023-03-20T19:51:05.656267+00:00] app.EMERGENCY: Hey ! I am writing in logs !! [] []
Plus généralement, on peut écrire une telle entrée :
<message> : le contenu de l’entrée log, sous forme de message explicite.
<context> : informations additionnelles (ou metadata) utiles pour la compréhension du message.
<extra-data> : informations additionnelles (non accessible depuis les assistants Symfony).
Channels
Les « channels » servent à identifier les entrées log. A chaque channel correspond un service monolog.logger.XXX (remplacez XXX par le nom du channel). Pour lister les « channels » utilisés dans Symfony, on liste les services correspondant :
Ce qui devrait afficher quelque chose de similaire à ceci :
Information for Service "monolog.handler.main"
==============================================
Stores to any stream resource
---------------- -------------------------------
Option Value
---------------- -------------------------------
Service ID monolog.handler.main
Class Monolog\Handler\StreamHandler
Tags kernel.reset (method: reset)
Calls pushProcessor
Public no
Synthetic no
Lazy no
Shared yes
Abstract no
Autowired no
Autoconfigured no
---------------- -------------------------------
Le service monolog.handler.main est donc une instance de la classe Monolog\Handler\StreamHandler. Faisant la même chose avec monolog.handler.console :
---------------- -----------------------------------------------
Option Value
---------------- -----------------------------------------------
Service ID monolog.handler.console
Class Symfony\Bridge\Monolog\Handler\ConsoleHandler
Tags kernel.event_subscriber
kernel.reset (method: reset)
container.no_preload
Public no
Synthetic no
Lazy no
Shared yes
Abstract no
Autowired no
Autoconfigured no
---------------- -----------------------------------------------
Cette fois on a une instance de la classe Symfony\Bridge\Monolog\Handler\ConsoleHandler.
On peut en déduire qu’avec Symfony, la classe du service défini le channel de l’entrée log.
Jusque là, on peut donc écrire le tableau suivant :
Logger
Classe
monolog.handler.main
StreamHandler
monolog.handler.console
ConsoleHandler
Tableau 7.1 – Correspondance channel/classe.
Si vous avez suivi le raisonnement, il vient qu’on sait désormais choisir le channel qu’on veut utiliser pour nos entrées : il suffit de correctement paramétrer l’injection de dépendance, en utilisant la classe associée au channel souhaité, en se référant à la liste des services Monolog.
Exemple : je veux utiliser le « channel » doctrine pour écrire dans mes logs. D’après la liste, son alias est monolog.logger.doctrine. Affichons le détail de ce service :
---------------- -------------------------------
Service ID monolog.logger.doctrine
Class Symfony\Bridge\Monolog\Logger
A ce stade nous avons deux façons de faire, et comme il ne s’agit de faire un cours sur l’injection de dépendance, j’en choisi une. Commençons par injecter l’interface LoggerInterface dans un contrôleur :
namespace App\Controller\Api;
use Symfony\Bundle\FrameworkBundle\Controller\AbstractController;
use Psr\Log\LoggerInterface;
class FooController extends AbstractController
{
/**
* @var LoggerInterface
*/
private $logger;
public function __construct(LoggerInterface $logger)
{
$this->logger = $logger;
}
public function edit()
{
$this->logger->info('Hey ! I am writing in logs !!');
$this->logger->critical('Oops something bad is happening');
}
}
Puis on spécifie le service à utiliser dans services.yaml :
On vérifie ensuite que le « channel » doctrine est bien utilisé :
[2023-01-06 13:07:46] doctrine.INFO: Hey ! I am writing in logs !! [] []
[2023-01-06 13:07:46] doctrine.CRITICAL: Oops something bad is happening [] []
Type de gestionnaire
Pour le moment on a utilisé un seul type de gestionnaire : stream. Il en existe d’autres :
fingers_crossed : ce gestionnaire stocke dans un buffer les entrées log qu’il reçoit. Si une entrée atteint un certain niveau d’erreur, cela déclenche le « vidage » du buffer en direction d’un autre handler. Plus d’explications dans le paragraphe dédié au gestionnaire finger_crossed.
rotating_file : permet de ne conserver les logs (dans le cas d’un stockage dans un système de fichier) qu’un certain nombre de jours. Plus d’explications dans le paragraphe dédié au gestionnaire rotating_file.
syslog : ce gestionnaire utilise la fonction php syslog pour l’entrée log reçue.
Plusieurs fichiers de logs
Grâce aux « channels », on va pouvoir séparer nos logs dans différents fichiers. Supposons que je veuille que les entrées log de doctrine soient stockées dans un fichier séparé. Il suffit de créer un gestionnaire qui ne va prendre en compte que le « channel » doctrine, et pas les autres :
On a maintenant un fichier /var/log/doctrine.dev.log qui contient, entre autres, nos deux entrées log :
[2018-10-06 21:28:35] doctrine.INFO: Hey ! I am writing in logs !! [] []
[2018-10-06 21:28:35] doctrine.CRITICAL: Oops something bad is happening [] []
Mais ces deux entrées se trouvent encore dans /var/log/dev.log. C’est normal, il faut modifier la configuration du gestionnaire principal pour qu’il écarte le channel doctrine :
Voyez la syntaxe pour exclure un channel : !channel_name.
Rotation des logs
Pour créer un gestionnaire qui prend en charge la rotation des logs, il suffit de le spécifier dans la clé de configuration :
monolog:
handlers:
main:
type: rotating_file ①
path: '%kernel.logs_dir%/%kernel.environment%.log'
level: debug
max_files: 10 ②
① → rotating_file indique au gestionnaire de prendre en charge la rotation des logs.
② → max_files indique la rétention du gestionnaire en jours (dans nos cas 10 jours). Au delà de cette limite, les fichiers sont détruits.
Dans ce cas, monolog crée un fichier par jour.
Filtrer les messages d’erreurs
En production, on a souvent besoin d’une journalisation réduite. Dans ce cas, on utilise le gestionnaire de type fingers_crossed qui va agir comme un buffer : il filtre toutes les entrées de la requête courante puis les transfère à un autre gestionnaire que lorsqu’une entrée log a un niveau d’erreur au moins équivalente à un seuil (qu’on défini bien sûr). Ce type de gestionnaire n’écrit rien du tout, il agit seulement comme un filtre.
Examinons la configuration du mode production de Symfony :
when@prod:
monolog:
handlers:
main:
type: fingers_crossed ①
action_level: error ②
handler: nested ③
excluded_http_codes: [404, 405]
buffer_size: 50 # How many messages should be saved? Prevent memory leaks
nested: ④
type: stream
path: var/log/prod.log ⑤
formatter: monolog.formatter.json
console:
type: console
process_psr_3_messages: false
channels: ["!event", "!doctrine"]
deprecation:
type: stream
channels: [deprecation]
path: php://stderr
① → création du gestionnaire de type finger_crossed.
② → le seuil de déclenchement est positionné à level.
③ → indique le gestionnaire à utiliser lors du dépassement du seuil.
④ → définition du gestionnaire qui est à utiliser lors du dépassement du seuil défini à la ligne ②.
⑤ → les messages sont écrit dans var/log/prod.log.
Le gestionnaire nested possède lui aussi une clé level. Il faut bien entendu que la valeur indiquée dans cette clé soit inférieure à la valeur indiquée dans ②.
L’intérêt de ce gestionnaire est majeur : s’il n’y a pas d’erreurs d’un certain niveau, on n’encombre pas les logs inutilement… Par contre, en cas d’erreur sérieuse, on a tous les messages d’erreur à notre disposition.
Cas particulier de la « containérisation »
Avec l’avènement de la containérisation, il peut être intéressant d’écrire les logs (en production) directement sur la sortie du container. Dans ce cas, il suffit de l’indiquer dans la clé path de la configuration du gestionnaire nested :
path: php://stderr
Logs système
Un autre type de gestionnaire intéressant est syslog. Il permet de stocker des entrées log via le système de log de la machine qui fait tourner l’application. Par exemple, en production, on peut ajouter un tel gestionnaire :
monolog:
handlers:
main:
type: fingers_crossed
action_level: error
handler: nested
excluded_404s:
# regex: exclude all 404 errors from the logs
- ^/
nested:
type: stream
path: "%kernel.logs_dir%/%kernel.environment%.log"
# still passed *all* logs, and still only logs error or higher
syslog_handler:
type: syslog
level: debug
Souvenez vous, les gestionnaires sont appelés dans l’ordre. Donc le gestionnaire syslog sera toujours appelé et il inscrira toutes les entrées dans les logs de la machine. Par exemple, sur une machine debian, le fichier est /var/log/syslog.
Happy debugging
Monolog est compatible firephp et chromephp. Il suffit d’ajouter un gestionnaire :
when@dev
monolog:
handlers:
firephp:
type: firephp
level: info
L’extension du même nom doit être installée et activée sur le navigateur. Après installation et configuration de l’extension, les logs apparaissent dans la console :
Ce gestionnaire est à réserver au mode dev bien sûr… 😝